chatbot
Chatbot [NLP Project]
Dataset
Corpus - Based on IIT Bhilai website.
QA dataset - We have created a custom dataset which includes the FAQ of IIT Bhilai.
Collection Procedure
IIT Bhilai Corpus
Downloaded the html files
wget \
--recursive \
--no-clobber \
--page-requisites \
--html-extension \
--no-check-certificate \
--convert-links \
--restrict-file-names=unix \
--domains iitbhilai.ac.in\
--no-parent \
https://www.iitbhilai.ac.in
From all the HTML files, we created the corpus.
for i in ${ls}
do
cat $i | pup 'div#content' text{} | sed '/^[[:space:]]*$/d' >> iit-corpus.txt
done
Cleaned the corpus from any css code.
QA Dataset
Scraped different websites like Quora, College-Dunia, etc.
Frontend
Its made using django framework. To start the server. Please run
source chating/.env
python manage.py runserver
Backend
Baseline Model
We have used word vectors (Word2Vec, FastText) to determine the embedding of different questions, and then tried
to find the Word Mover’s distance between the asked question and available questions, to give ans answer.
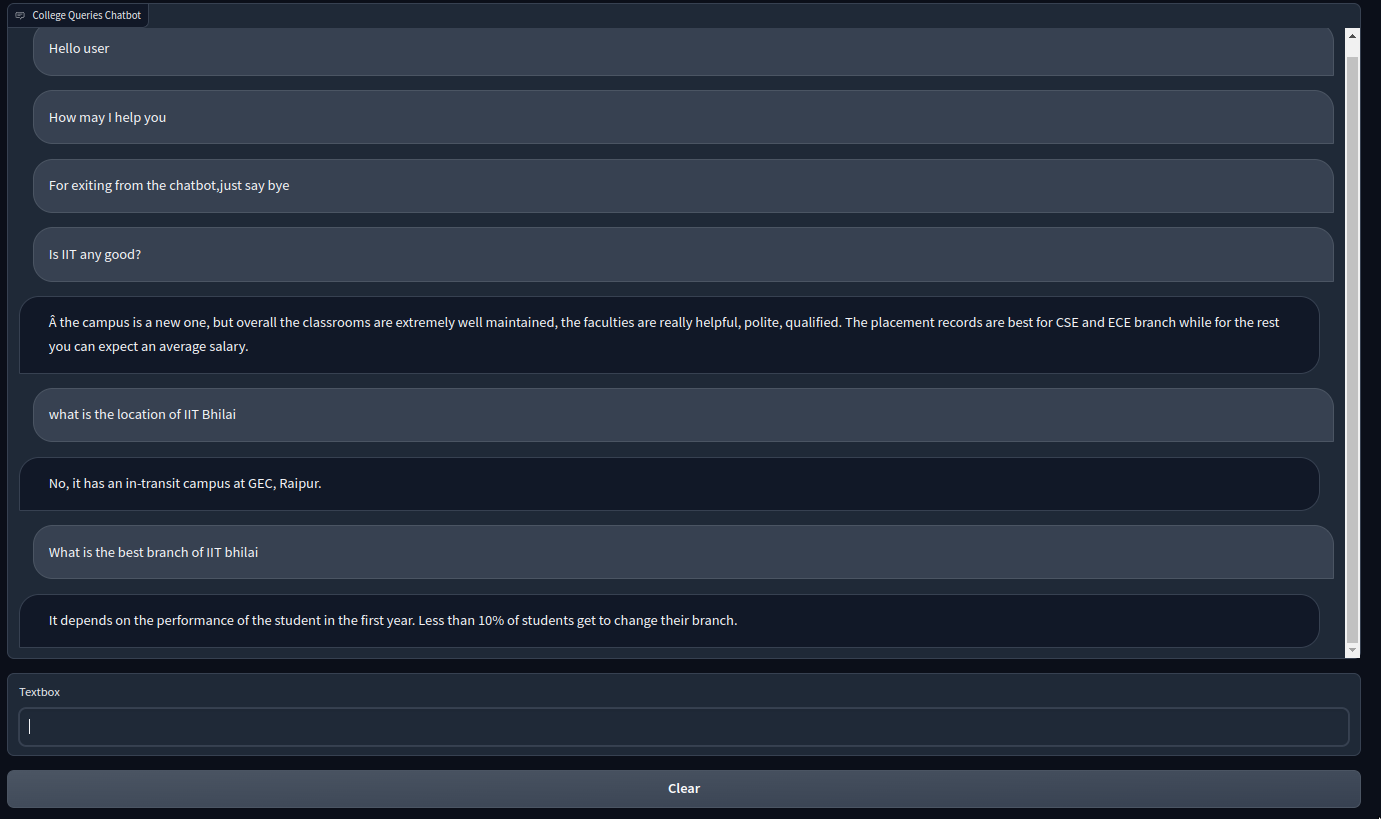
To run the chatbot, execute
python chatbot.py
TODO
- Download the GPT4All model from git repo.
- Install langchain
pip install langchain - Write a langchain script to create a vector Db and create the embeddings.
- Scrap the IIT Bhilai Website using scrappy. Follow Abhishek Thakur Video.
- Write a basic chatbot
- Write a gradio script for UI for the chatbot
BERT Model
Using the custom dataset, we fine tuned the bart-base-uncased BERT model on Masked Language Modelling task to train it on the domain of IIT Corpus. Using the fine tuned BERT model, we trained it on the custom QA dataset for our chatbot.
Presentation
Please check the ppt for more details.